https://plantegg.github.io/2019/12/24/Linux%E5%86%85%E6%A0%B8%E7%89%88%E6%9C%AC%E5%8D%87%E7%BA%A7%EF%BC%8C%E6%80%A7%E8%83%BD%E5%88%B0%E5%BA%95%E6%8F%90%E5%8D%87%E5%A4%9A%E5%B0%91%EF%BC%9F%E6%8B%BF%E6%95%B0%E6%8D%AE%E8%AF%B4%E8%AF%9D/
背景
X 产品在公有云售卖一直使用的2.6.32的内核,有点老并且有些内核配套工具不能用,于是想升级一下内核版本。预期新内核的性能不能比2.6.32差
以下不作特殊说明的话都是在相同核数的Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz下得到的数据,最后还会比较相同内核下不同机型/CPU型号的性能差异。
场景都是用sysbench 100个并发跑点查。
结论
先说大家关心的数据,最终4.19内核性能比2.6.32好将近30%,建议大家升级新内核,不需要做任何改动,尤其是Java应用(不同场景会有差异)
本次比较的场景是Java应用的Proxy类服务,主要瓶颈是网络消耗,类似于MaxScale。后面有一个简单的MySQL Server场景下2.6.32和4.19的比较,性能也有33%的提升。
2.6.32性能数据
升级前先看看目前的性能数据好对比(以下各个场景都是CPU基本跑到85%)
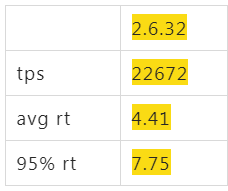
一波N折的4.19
阿里云上默认买到的ALinux2 OS(4.19),同样配置跑起来后,tps只有16000,比2.6.32的22000差了不少,心里只能暗暗骂几句坑爹的货,看了下各项指标,看不出来什么问题,就像是CPU能力不行一样。如果这个时候直接找内核同学,估计他们心里会说 X 是个什么东西?是不是你们测试有问题,是不是你们配置的问题,不要来坑我,内核性能我们每次发布都在实验室里跑过了,肯定是你们的应用问题。
所以要找到一个公认的场景下的性能差异。幸好通过qperf发现了一些性能差异。
通过qperf来比较差异
大包的情况下性能基本差不多,小包上差别还是很明显
qperf -t 40 -oo msg_size:1 4.19 tcp_bw tcp_lat
tcp_bw:bw = 2.13 MB/sec
tcp_lat:latency = 224 us
tcp_bw:bw = 2.15 MB/sec
tcp_lat:latency = 226 usqperf -t 40 -oo msg_size:1 2.6.32 tcp_bw tcp_lat
tcp_bw:bw = 82 MB/sec
tcp_lat:latency = 188 us
tcp_bw:bw = 90.4 MB/sec
tcp_lat:latency = 229 us
这下不用担心内核同学怼回来了,拿着这个数据直接找他们,可以稳定重现。
经过内核同学排查后,发现默认镜像做了一些安全加固,简而言之就是CPU拿出一部分资源做了其它事情,比如旁路攻击的补丁之类的,需要关掉(因为 X 的OS只给我们自己用,上面部署的代码都是X 产品自己的代码,没有客户代码,客户也不能够ssh连上X 产品节点)
去掉 melt、spec 能到20000, 去掉sonypatch能到21000
关闭的办法在grub配置中增加这些参数:
nopti nospectre_v2 nospectre_v1 l1tf=off nospec_store_bypass_disable no_stf_barrier mds=off mitigations=off
关掉之后的状态看起来是这样的:
$sudo cat /sys/devices/system/cpu/vulnerabilities/*
Mitigation: PTE Inversion
Vulnerable; SMT Host state unknown
Vulnerable
Vulnerable
Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
Vulnerable, STIBP: disabled
这块参考阿里云文档 和这个
4.9版本的内核性能
但是性能还是不符合预期,总是比2.6.32差点。在中间经过几个星期排查不能解决问题,陷入僵局的过程中,尝试了一下4.9内核,果然有惊喜。
下图中对4.9的内核版本验证发现,tps能到24000,明显比2.6.32要好,所以传说中的新内核版本性能要好看来是真的,这下坚定了升级的念头,同时也看到了兜底的方案–最差就升级到4.9
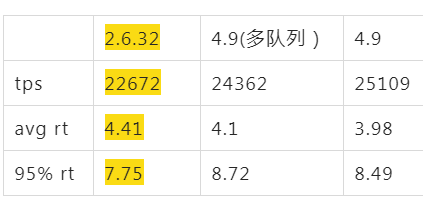
多队列是指网卡多队列功能,也是这次升级的一个动力。看起来在没达到单核瓶颈前,网卡多队列性能反而差点,这也符合预期
继续分析为什么4.19比4.9差了这么多
4.9和4.19这两个内核版本隔的近,比较好对比分析内核参数差异,4.19跟2.6.32差太多,比较起来很困难。
最终仔细对比了两者配置的差异,发现ALinux的4.19中 transparent_hugepage 是 madvise ,这对Java应用来说可不是太友好:
$cat /sys/kernel/mm/transparent_hugepage/enabled
always [madvise] never
将其改到 always 后4.19的tps终于稳定在了28300
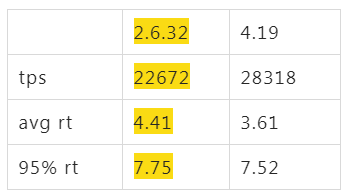
这个过程中花了两个月的一些其他折腾就不多说了,主要是内核补丁和transparent_hugepage导致了性能差异。
transparent_hugepage,在redis、mongodb、memcache等场景(很多小内存分配)是推荐关闭的,所以要根据不同的业务场景来选择开关。
透明大页打开后在内存紧张的时候会触发sys飙高对业务会导致不可预期的抖动,同时存在已知内存泄漏的问题,我们建议是关掉的,如果需要使用,建议使用madvise方式或者hugetlbpage
一些内核版本、机型和CPU的总结
到此终于看到不需要应用做什么改变,整体性能将近有30%的提升。 在这个测试过程中发现不同CPU对性能影响很明显,相同机型也有不同的CPU型号(性能差异在20%以上–这个太坑了)
性能方面 4.19>4.9>2.6.32
没有做3.10内核版本的比较
以下仅作为大家选择ECS的时候做参考。
不同机型/CPU对性能的影响
还是先说结论:
- CPU:内存为1:2机型的性能排序:c6->c5->sn1ne->hfc5->s1
- CPU:内存为1:4机型的性能排序:g6->g5->sn2ne->hfg5->sn2
性能差异主要来源于CPU型号的不同
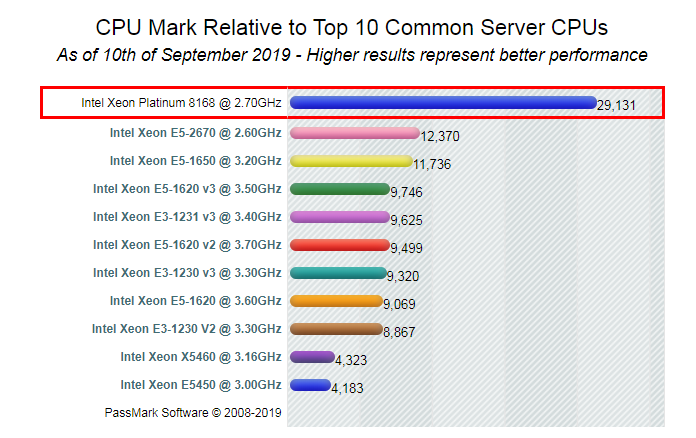
c6/g6: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
c5/g5/sn1ne/sn2ne: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz
8269比8163大概好5-10%,价格便宜一点点,8163比E5-2682好20%以上,价格便宜10%(该买什么机型你懂了吧,价格是指整个ECS,而不是单指CPU)
要特别注意sn1ne/sn2ne 是8163和E5-2682 两种CPU型号随机的,如果买到的是E5-2682就自认倒霉吧
C5的CPU都是8163,相比sn1ne价格便宜10%,网卡性能也一样。但是8核以上的sn1ne机型就把网络性能拉开了(价格还是维持c5便宜10%),从点查场景的测试来看网络不会成为瓶颈,到16核机型网卡多队列才会需要打开。
顺便给一下部分机型的包月价格比较:
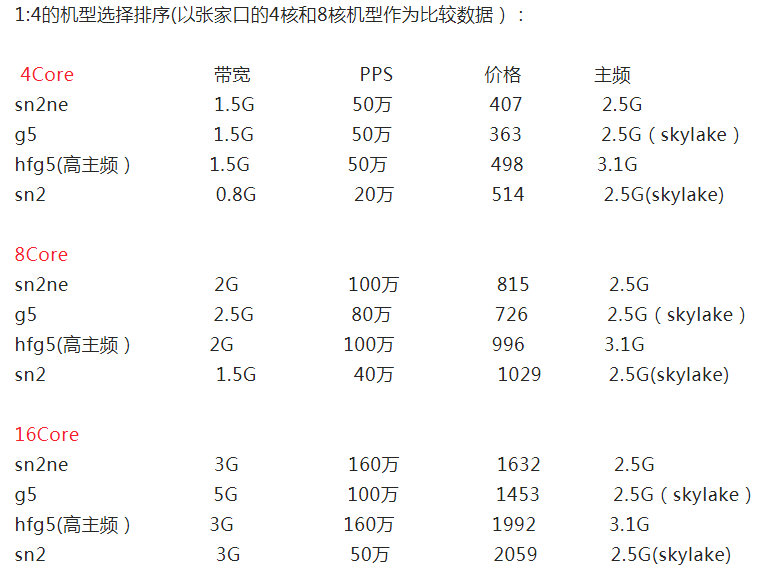
官方给出的CPU数据:
4.19内核在MySQL Server场景下的性能比较
这只是sysbench点查场景粗略比较,因为本次的目标是对X 产品性能的改进
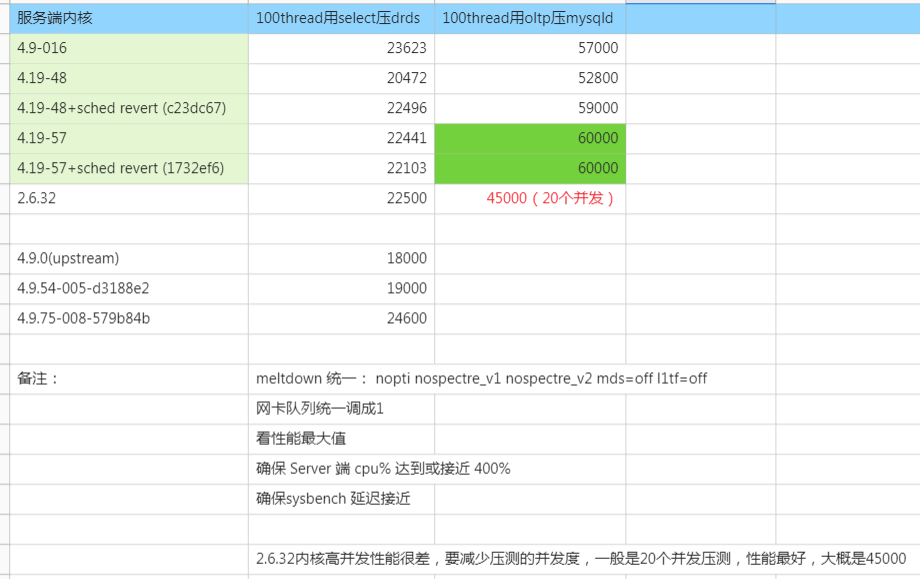
(以上表格数据主要由 内核团队和我一起测试得到)
重点注意2.6.32不但tps差30%,并发能力也差的比较多,如果同样用100个并发压2.6.32上的MySQL,TPS在30000左右。只有在减少并发到20个的时候压测才能达到图中最好的tps峰值:45000.
新内核除了性能提升外带来的便利性
升级内核带来的性能提升只是在极端场景下才会需要,大部分时候我们希望节省开发人员的时间,提升工作效率。于是X 产品在新内核的基础上定制如下一些便利的工具。
麻烦的网络重传率
通过tsar或者其它方式发现网络重传率有点高,有可能是别的管理端口重传率高,有可能是往外连其它服务端口重传率高等,尤其是在整体流量小的情况下一点点管理端口的重传包拉升了整个机器的重传率,严重干扰了问题排查,所以需要进一步确认重传发生在哪个进程的哪个端口上,是否真正影响了我们的业务。
在2.6.32内核下的排查过程是:抓包,然后写脚本分析(或者下载到本地通过wireshark分析),整个过程比较麻烦,需要的时间也比较长。那么在新镜像中我们可以利用内核自带的bcc来快速得到这些信息
sudo /usr/share/bcc/tools/tcpretrans -l
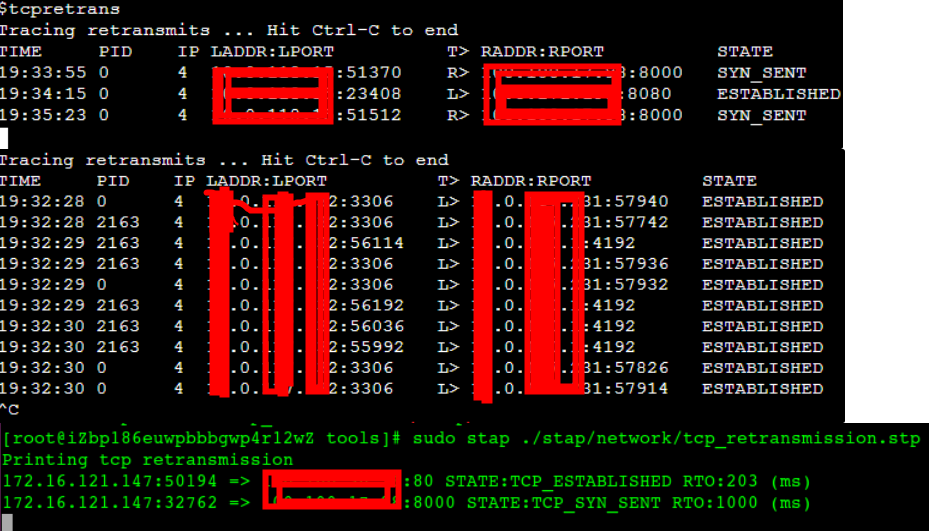
从截图可以看到重传时间、pid、tcp四元组、状态,针对重传发生的端口和阶段(SYN_SENT握手、ESTABLISHED)可以快速推断导致重传的不同原因。
再也不需要像以前一样抓包、下载、写脚本分析了。
通过perf top直接看Java函数的CPU消耗
这个大家都比较了解,不多说,主要是top的时候能够把java函数给关联上,直接看截图:
sh ~/tools/perf-map-agent/bin/create-java-perf-map.sh pid
sudo perf top
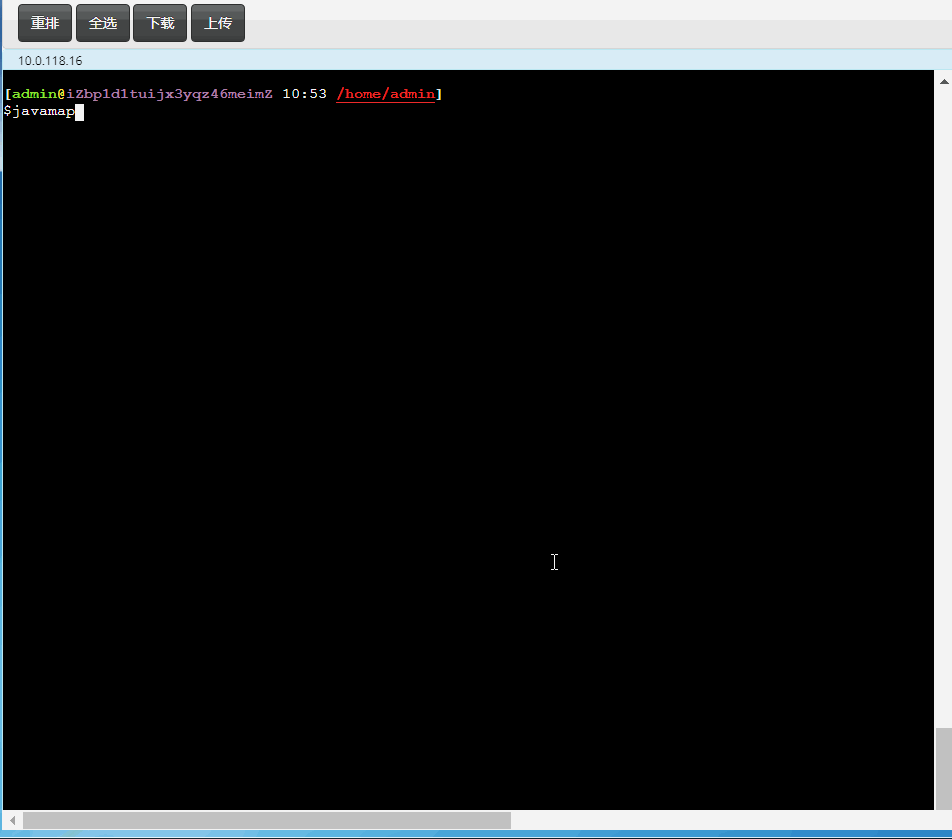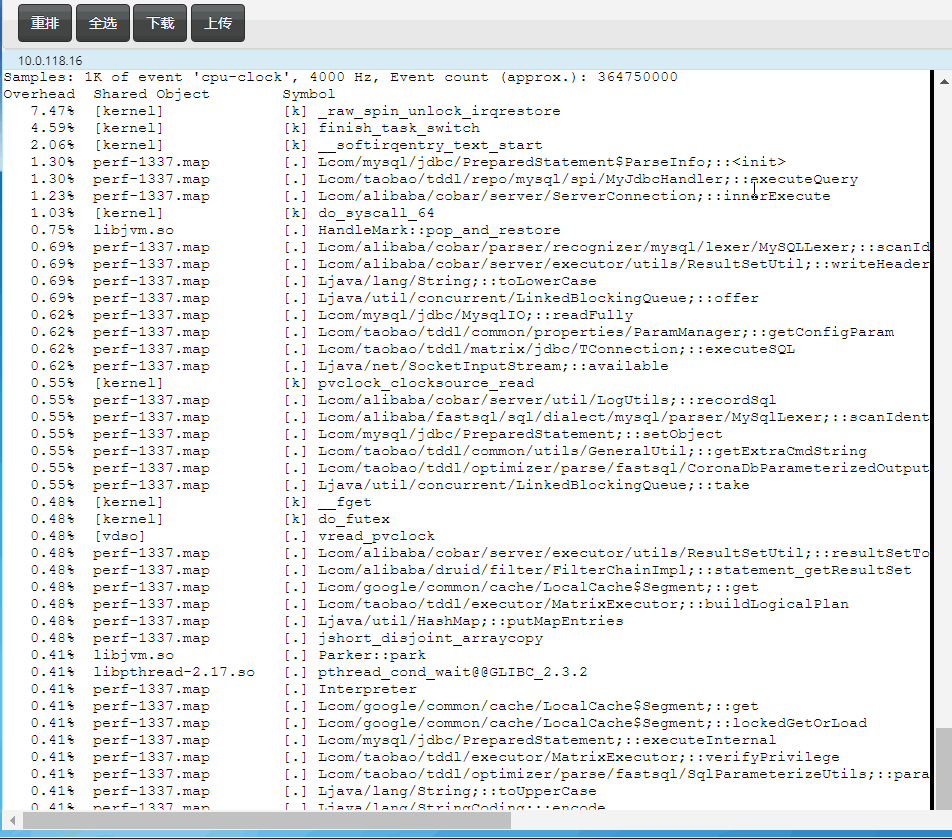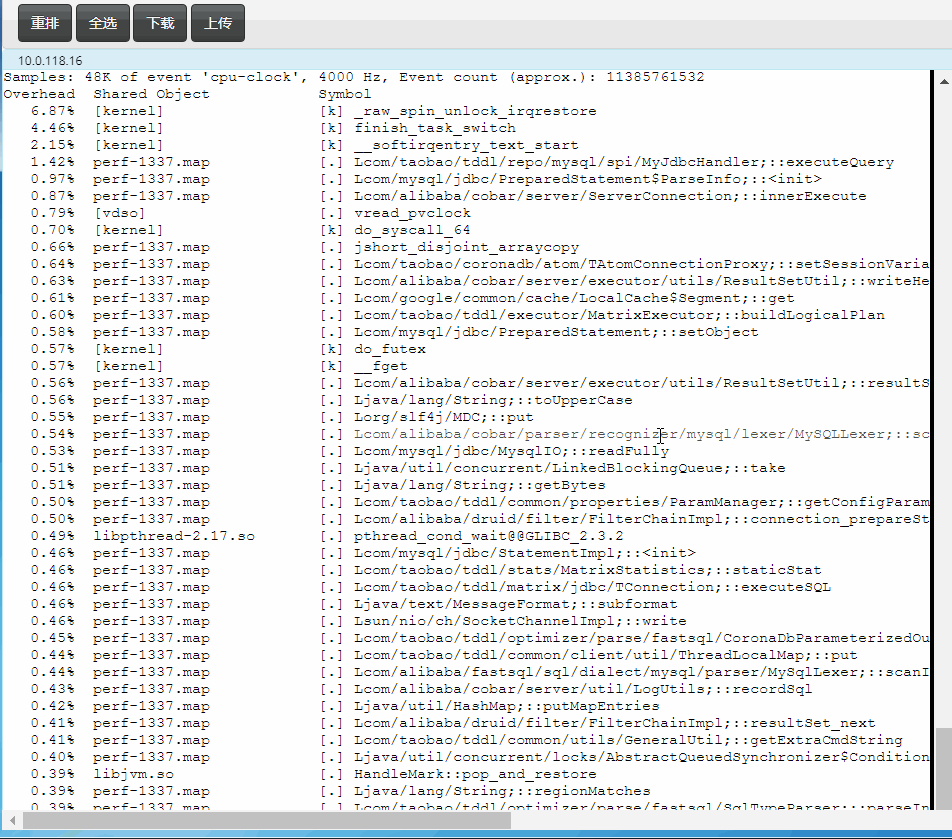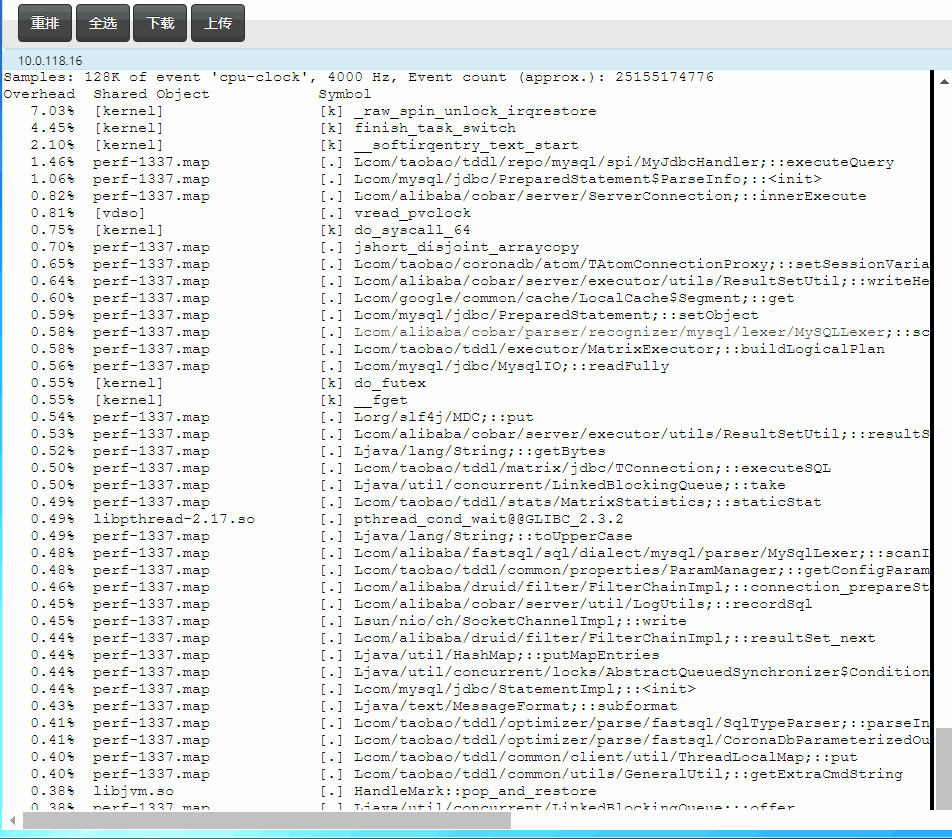
快速定位Java中的锁等待
如果CPU跑不起来,可能会存在锁瓶颈,需要快速找到它们
如下测试中上面的11万tps是解决掉锁后得到的,下面的4万tps是没解决锁等待前的tps:
#[ 210s] threads: 400, tps: 0.00, reads/s: 115845.43, writes/s: 0.00, response time: 7.57ms (95%)
#[ 220s] threads: 400, tps: 0.00, reads/s: 116453.12, writes/s: 0.00, response time: 7.28ms (95%)
#[ 230s] threads: 400, tps: 0.00, reads/s: 116400.31, writes/s: 0.00, response time: 7.33ms (95%)
#[ 240s] threads: 400, tps: 0.00, reads/s: 116025.35, writes/s: 0.00, response time: 7.48ms (95%)#[ 250s] threads: 400, tps: 0.00, reads/s: 45260.97, writes/s: 0.00, response time: 29.57ms (95%)
#[ 260s] threads: 400, tps: 0.00, reads/s: 41598.41, writes/s: 0.00, response time: 29.07ms (95%)
#[ 270s] threads: 400, tps: 0.00, reads/s: 41939.98, writes/s: 0.00, response time: 28.96ms (95%)
#[ 280s] threads: 400, tps: 0.00, reads/s: 40875.48, writes/s: 0.00, response time: 29.16ms (95%)
#[ 290s] threads: 400, tps: 0.00, reads/s: 41053.73, writes/s: 0.00, response time: 29.07ms (95%)
下面这行命令得到如下等锁的top 10堆栈(async-profiler):
$~/tools/async-profiler/profiler.sh -e lock -d 5 1560--- 1687260767618 ns (100.00%), 91083 samples[ 0] ch.qos.logback.classic.sift.SiftingAppender[ 1] ch.qos.logback.core.AppenderBase.doAppend[ 2] ch.qos.logback.core.spi.AppenderAttachableImpl.appendLoopOnAppenders[ 3] ch.qos.logback.classic.Logger.appendLoopOnAppenders[ 4] ch.qos.logback.classic.Logger.callAppenders[ 5] ch.qos.logback.classic.Logger.buildLoggingEventAndAppend[ 6] ch.qos.logback.classic.Logger.filterAndLog_0_Or3Plus[ 7] ch.qos.logback.classic.Logger.info[ 8] com.*****.logger.slf4j.Slf4jLogger.info[ 9] com.*****.utils.logger.support.FailsafeLogger.info[10] com.*****.util.LogUtils.recordSql"ServerExecutor-3-thread-480" #753 daemon prio=5 os_prio=0 tid=0x00007f8265842000 nid=0x26f1 waiting for monitor entry [0x00007f82270bf000]java.lang.Thread.State: BLOCKED (on object monitor)at ch.qos.logback.core.AppenderBase.doAppend(AppenderBase.java:64)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)at ch.qos.logback.core.spi.AppenderAttachableImpl.appendLoopOnAppenders(AppenderAttachableImpl.java:48)at ch.qos.logback.classic.Logger.appendLoopOnAppenders(Logger.java:282)at ch.qos.logback.classic.Logger.callAppenders(Logger.java:269)at ch.qos.logback.classic.Logger.buildLoggingEventAndAppend(Logger.java:470)at ch.qos.logback.classic.Logger.filterAndLog_0_Or3Plus(Logger.java:424)at ch.qos.logback.classic.Logger.info(Logger.java:628)at com.****.utils.logger.slf4j.Slf4jLogger.info(Slf4jLogger.java:42)at com.****.utils.logger.support.FailsafeLogger.info(FailsafeLogger.java:102)at com.****.util.LogUtils.recordSql(LogUtils.java:115)ns percent samples top---------- ------- ------- ---
160442633302 99.99% 38366 ch.qos.logback.classic.sift.SiftingAppender12480081 0.01% 19 java.util.Properties3059572 0.00% 9 com.***.$$$.common.IdGenerator244394 0.00% 1 java.lang.Object
堆栈中也可以看到大量的:
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- locked <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
当然还有很多其他爽得要死的命令,比如一键生成火焰图等,不再一一列举,可以从业务层面的需要从这次镜像升级的便利中将他们固化到镜像中,以后排查问题不再需要繁琐的安装、配置、调试过程了。
跟内核无关的应用层的优化
到此我们基本不用任何改动得到了30%的性能提升,但是对整个应用来说,通过以上工具让我们看到了一些明显的问题,还可以从应用层面继续提升性能。
如上描述通过锁排序定位到logback确实会出现锁瓶颈,同时在一些客户场景中,因为网盘的抖动也带来了灾难性的影响,所以日志需要异步处理,经过异步化后tps 达到了32000,关键的是rt 95线下降明显,这个rt下降对X 产品这种Proxy类型的应用是非常重要的(经常被客户指责多了一层转发,rt增加了)。
日志异步化和使用协程后的性能数据:
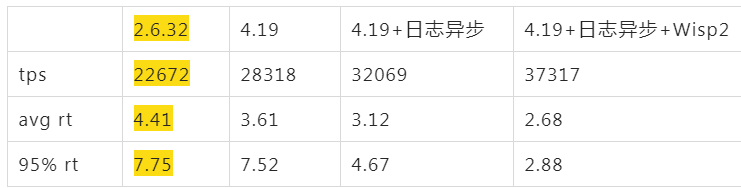
Wisp2 协程带来的红利
参考 @梁希 的 Wisp2: 开箱即用的Java协程:
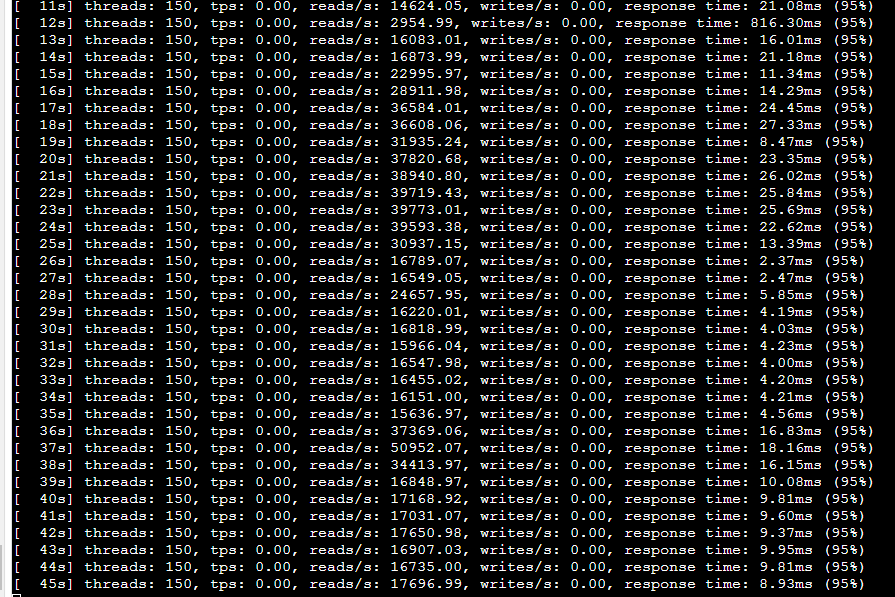
在整个测试过程中都很顺利,只是发现Wisp2在阻塞不明显的场景下,抖的厉害。简单来说就是压力比较大的话Wisp2表现很稳定,一旦压力一般(这是大部分应用场景),Wisp2表现像是一会是协程状态,一会是没开携程状态,系统的CS也变化很大。
比如同一测试过程中tps抖动明显,从15000到50000:
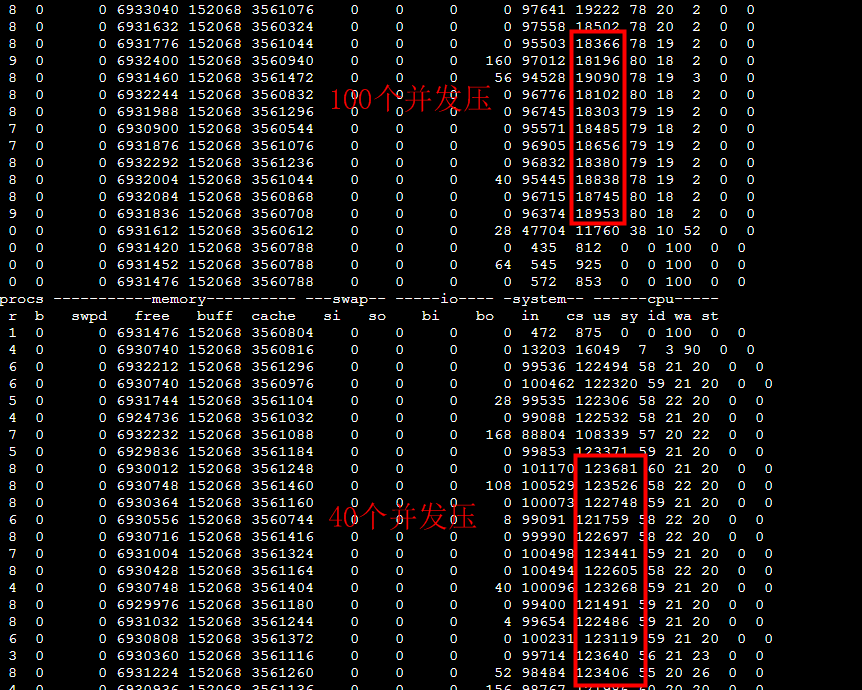
100个并发的时候cs很小,40个并发的时候cs反而要大很多:
最终在 @梁希 同学的攻关下发布了新的jdk版本,问题基本都解决了。不但tps提升明显,rt也有很大的下降。
致谢
感谢 @夷则 团队对这次内核版本升级的支持,感谢 @雏雁 @飞绪 @李靖轩(无牙) @齐江(窅默) @梁希 等大佬的支持。
最终应用不需要任何改动可以得到 30%的性能提升,经过开启协程等优化后应用有将近80%的性能提升,同时平均rt下降了到原来的60%,rt 95线下降到原来的40%。
快点升级你们的内核,用上协程吧。同时考虑下在你们的应用中用上X 产品。